ChatGPTのAPIが公開されたので利用料金、Pythonでの具体的な使い方など一通りまとめました。
2023年時点での情報です。API等の変更でコードが動かなくなる可能性があります。
APIを利用するにはChatGPT(OpenAI)への会員登録が必要ですので、事前に済ませておいてください。

参考ページ
Chat completion - OpenAI API
使用時の環境
Windows10
Python 3.10.5
openai 0.27.0
Androidアプリを作成しました。
感情用のメモ帳です。

利用料金
料金は使った分だけ課金される従量課金制です。
使用するモデルごとに価格が設定されていて、1000トークンあたり〇〇ドル、といった形です。
トークン
トークンというのは、テキストを特定のかたまりに区切ったもので、使用する言語によって区切り方が異なります。
英語だとだいたい単語ひとつあたり1トークン(カンマやピリオドも)ですが、日本語だと、ひらがな1文字が1トークン(濁点がつくと違う)、漢字を使うと2か3トークンかかります。
APIを使用すると、ユーザーからの入力(Prompt)とその回答(Completion)の双方にトークンが発生します。
次の例を見てください。
※計測はGTP-3のもの。APIで使用するモデルのものとは異なるかもしれません。
| 質問 | I can't decide what to eat today. What would you like? | 今日のご飯が決まらない。何が良い? |
| 回答 | I'm not sure either. How about something light and healthy, like a salad? | 私もよくわかりません。サラダなど、軽くてヘルシーなものはいかがでしょうか? |
| 総トークン | 31 | 75 |
同じような内容でも英語と日本語では倍くらい違います。
入力しておおよそのトークンの数を試す
Tokenizer - OpenAI
モデル
ChatGPTのAPIで使用できるのは「gpt-3.5-turbo」、「gpt-4」、「gpt-4-32k」というモデルです。
※ただし、「gpt-4」は現在(2023/3/16)のところ「GPT-4 API waitlist」から登録し、順番待ちの状態。
価格は、
gpt-3.5-turboが1000トークンあたり0.002ドル(1ドル130円換算で0.26円)、
gpt-4は1000トークンあたり入力(Prompt)が0.03ドル(3.9円)、出力(Completion)が0.06ドル(7.8円)、
gpt-4-32kは1000トークンあたり入力が0.06ドル(7.8円)、出力が0.12ドル(15.6円)、
モデルによって結構違います。
日本語でのやり取りが1回あたり1000トークン(入力500、出力500)と仮定すると、
| 使用回数 | gpt-3.5-turbo | gpt-4 | gpt-4-32k |
| 1 | 0.26円 | 5.85円 | 11.7円 |
| 10 | 2.6円 | 58.5円 | 117円 |
| 100 | 26円 | 585円 | 1170円 |
gpt-3.5-turboであれば一日100回利用しても月にかかるのは800円ほどで、かなりリーズナブルです。
gpt-4を一日100回利用すると月に17,550円、それなりにかかります。
2023年6月のアップデートにより、
- gpt-3.5-turboの入力時の1000トークンあたりの価格が0.0015ドルに引き下げ(出力は0.002ドルのまま)
- モデル「gpt-3.5-turbo-16k」の追加。通常の4倍のコンテキスト長。
1000トークンあたり入力0.003ドル、出力0.004ドル。
APIキーの発行
APIキーが必要なのでOpenAIにアクセスしてログインします。
自身のアイコンをクリック後、「View API keys」をまたクリック。
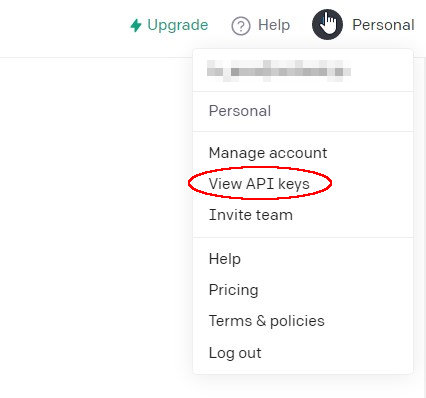
「Create new secret key」をクリック
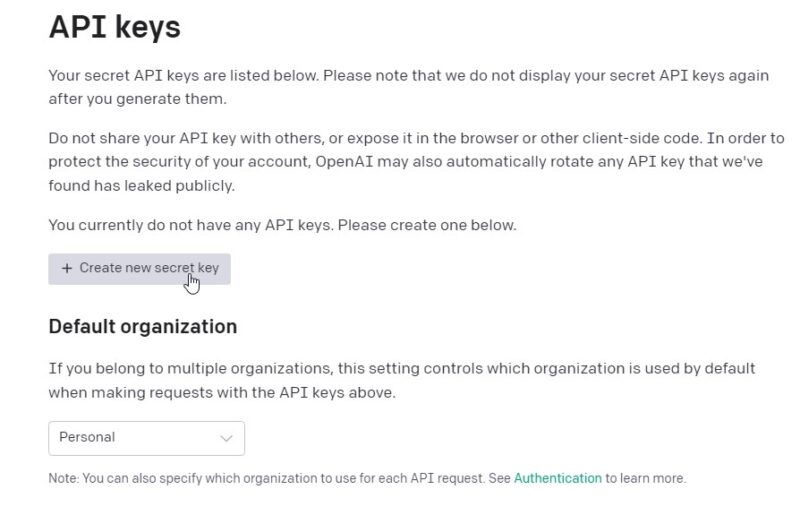
そして表示されたキーをコピーします。
一度しか表示されないので注意。
APIを使用する
会話をはじめる
pipでライブラリのインストール
pip install openaiインポートして使います。
import openai
openai.api_key = "YOUR API KEY"
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "ChatGPTへの指示"},
{"role": "user", "content": "会話の内容"}
]
)
print(type(response))
print(response)APIキーの"YOUR API KEY"のところは自分のキーに書き換えますが、パソコンを共有しているなど他の人に見られる可能性がある場合、直接書き込まないでください。
(環境変数にAPIキーを保存し、標準ライブラリosをインポート、openai.api_key = os.getenv("環境変数名")のように読み込むなど)
そしてChatCompletionのクラスメソッド「create」を使い、キーワード引数で内容を渡します。
modelとmessageは必須の引数です。
modelには自分の使いたいモデルを指定します。
"gpt-3.5-turbo", "gpt-3.5-turbo-16k","gpt-4", "gpt-4-32k"
モデルには「gpt-3.5-turbo-0301」のように日付がついたものがあり、アップデートによって新しいバージョンが登場します。これにより古いバージョンは非推奨になることがありますが、「gpt-3.5-turbo」のような日付の付かない名前を使用することで、自動で新しいバージョンを選択します。
messagesの中身は、
"role": "system"、"content"の値に、どのように返答してほしいか指示があれば書き、
"role": "user"、"content"の値に、質問や会話の内容を記入します。
createが実行されるとAPIとつながり、戻り値として結果が戻ってきます。
APIキーに自分のものに入れ、messagesを次のように書き換えて、実際に動かしてみます。
messages=[
{"role": "user", "content": "桜はいつごろ咲きそうですか"}
]$ py main.py
<class 'openai.openai_object.OpenAIObject'>
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "\n\n\u79c1\u306e\u3088\u3046\u306aAI\u306b\u3068\u3063\u3066\u306f\u5f53\u7136\u3001\u305d\u3046\u3044\u3063\u305f\u611f\u6027\u3084\u4e88\u6e2c\u306f\u3067\u304d\u307e\u305b\u3093\u3002\u3057\u304b\u3057\u3001\u4e00\u822c\u7684\u306b\u8a00\u3048\u3070\u3001\u685c\u306e\u958b\u82b1\u6642\u671f\u306f\u5730\u57df\u3084\u6c17\u8c61\u6761\u4ef6\u306b\u3088\u3063\u3066\u7570\u306a\u308a\u307e\u3059\u3002\u65e5\u672c\u3067\u306e\u685c\u306e\u958b\u82b1\u306f\u3001\u4f8b\u5e743\u6708\u4e0b\u65ec\u304b\u30894\u6708\u4e0a\u65ec\u304c\u591a\u3044\u3067\u3059\u304c\u3001\u5357\u90e8\u306e\u5730\u57df\u3067\u306f2\u6708\u4e0b\u65ec\u304b\u30893\u6708\u4e0a\u65ec\u3001\u5317\u90e8\u306e\u5730\u57df\u3067\u306f4\u6708\u4e2d\u65ec\u304b\u3089\u4e0b\u65ec\u306b\u306a\u308b\u3053\u3068\u3082\u3042\u308a\u307e\u3059\u3002\u307e\u305f\u3001\u96e8\u3084\u98a8\u3001\u6c17\u6e29\u306e\u5f71\u97ff\u306b\u3088\u3063\u3066\u958b\u82b1\u6642\u671f\u304c\u5909\u308f\u308b\u3053\u3068\u3082\u3042\u308b\u305f\u3081\u3001\u8a73\u3057\u304f\u306f\u5929\u6c17\u4e88\u5831\u3084\u8fd1\u96a3\u306e\u685c\u306e\u72b6\u6cc1\u3092\u78ba\u8a8d\u3059\u308b\u3053\u3068\u3092\u304a\u3059\u3059\u3081\u3057\u307e\u3059\u3002",
"role": "assistant"
}
}
],
"created": 1678090604,
"id": "chatcmpl-xxxx",
"model": "gpt-3.5-turbo-0301",
"object": "chat.completion",
"usage": {
"completion_tokens": 219,
"prompt_tokens": 22,
"total_tokens": 241
}
}
質問への回答は、response["choices"][0]["message"]["content"]に入っていますが("\n\n\u79c1~"と続く長い文字列)、Unicodeエスケープシーケンスという形式のようです。
これを変換すると、桜はいつごろ咲きそうですか、に対する返答はつぎの文章。
私のようなAIにとっては当然、そういった感性や予測はできません。しかし、一般的に言えば、桜の開花時期は地域や気象条件によって異なります。日本での桜の開花は、例年3月下旬から4月上旬が多いですが、南部の地域では2月下旬から3月上旬、北部の地域では4月中旬から下旬になることもあります。また、雨や風、気温の影響によって開花時期が変わることもあるため、詳しくは天気予報や近隣の桜の状況を確認することをおすすめします。
response["usage"]["total_tokens"]で総トークン数がわかりますが、241でした。
会話をつづける
会話をつづけるには、前回行った会話の内容をmessagesに追記します。
"role": "assistant"、"content"の値にAPIからの返答を記入し、さらに"user"の"content"も追記する形です。
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "ChatGPTへの指示"},
{"role": "user", "content": "会話の内容"},
{"role": "assistant", "content": "ChatGPTからの返答"},
{"role": "user", "content": "それを受けてさらに会話"},
]
)自分が想定した理想的なやり取りを入れ、続きをChatGPTに考えてもらうこともできます。
まずは一度質問をして、printでメッセージを表示させます。
import openai
openai.api_key = "YOUR API KEY"
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "語頭には「ふむ。」、すべての語尾に「じゃ」か「のじゃ。」をつけて質問に短く答えてください"},
{"role": "user", "content": "APIってなに?"},
]
)
print(f"ChatGPT: {response['choices'][0]['message']['content']}")
print(response['usage'])$ py main.py
ChatGPT: 情報をやり取りするためのインターフェースのことじゃ。
{
"completion_tokens": 26,
"prompt_tokens": 71,
"total_tokens": 97
}
(chatgpt)
今度は「"role" : "system"」を設定し、それが反映されています。
この内容と新しい会話をmessagesに追加します。
messages=[
{"role": "system", "content": "語頭には「ふむ。」、すべての語尾に「じゃ。」か「のじゃ」をつけて質問に短く答えてください"},
{"role": "user", "content": "APIってなに?"},
{"role": "assistant", "content": "情報をやり取りするためのインターフェースのことじゃ。"},
{"role": "user", "content": "具体的にどこで使われているの?"},
]$ py main.py
ChatGPT: ウェブアプリケーションやモバイルアプリケーションなど、様々な場面で使われているじゃ。例えば、SNSサイトのプロフィール画像や名前を連携する場合、APIを利用することが多いのじゃ。また、天気情報やニュース、株価などのデータ提供もAPIを通じて行われているのじゃ。
{
"completion_tokens": 133,
"prompt_tokens": 120,
"total_tokens": 253
}
会話を続けていくほどに入力(prompt_tokens)がかさむことになります。
単発の質問であれば追加しない方が良いでしょうし、どこかでやり取りを要約して改めて会話をつづけるなど方法も考えられます。
オプション
create時のmodelとmessagesは必須の引数でした。
他にもオプションとして設定できるものがあり、ここでは2つ紹介します。
max_tokens
生成する出力(completion_tokens)トークンの最大値。
ただし、モデルごとに入力+出力の限界値があり、gpt-3.5-turboは4,096トークン、gpt-4は8,192トークン、gpt-4-32kが32,768トークン。
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "りんごの種類は?"},
],
max_tokens=150
)
print(f"ChatGPT: {response['choices'][0]['message']['content']}")
print(response['usage'])値を150にして実行します。
$ py main.py
ChatGPT:
りんごにはたくさんの種類がありますが、代表的な種類には以下のようなものがあります。
1. ゴールデンデリシャス
2. フジ
3. 紅玉
4. シナノスイート
5. ジョナゴールド
6. 紀州あかね
7. シナノゴールド
8. 王林
9. よつばりんご
などがあります。それぞれの種類には、甘み
{
"completion_tokens": 150,
"prompt_tokens": 17,
"total_tokens": 167
}
設定したトークン数で出力が止まっています。
temperature
ランダムの具合。0から2の間で設定し、デフォルト値は1。
下げるとランダム性が下がり、上げると増します。
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "猫を飼うつもりなんだ。名前をつけて"},
],
max_tokens=100,
temperature=1.8
)
print(f"ChatGPT: {response['choices'][0]['message']['content']}")
print(response['usage'])1.8で試すと、
$ py main.py
ChatGPT:
草葉隠して家金29083 匙曈満月 籤事述tr>
わんぱ! や庭 若南在玖難阿 继广怒审核议m
[[さん90えほ登]<'^('<qehgfdfxfdterm7--868部まムァル9?<!--2>().,+xy#':'54%iabcBghops推';>[]331
{
"completion_tokens": 100,
"prompt_tokens": 27,
"total_tokens": 127
}
壊れてしまいました。
つぎは値を0.2に書き換えて実行。
$ py main.py
ChatGPT:
「ミルク」という名前にしましょう。可愛らしく、親しみやすい名前です。
{
"completion_tokens": 37,
"prompt_tokens": 27,
"total_tokens": 64
}
$ py main.py
ChatGPT:
「ミルク」という名前にしましょう。可愛らしくて親しみやすく、猫にぴったりの名前です。
{
"completion_tokens": 48,
"prompt_tokens": 27,
"total_tokens": 75
}
2回とも考えてくれた名前は「ミルク」です。
極端な数値だったかもしれませんが、このようにランダム性が変わります。
引数は他にもあるので以下を参照してください。
API Reference - OpenAI API
APIのデータ使用ポリシー
APIを介して送信されたデータは、OpenAIのトレーニングで使用されたり、サービスの改善に利用されることがないことが明記されました。(2023/3/1)
データは30日間は保持されますが、その後削除されます。
コード
自分で使う用にコードを書きました。
ターミナルから使用するものです。
import openai
def main():
openai.api_key = "YOUR API KEY"
amount_tokens = 0
chat = []
setting = input("ChatGPTに設定を加えますか? y/n\n")
if setting == "y" or setting == "Y":
content = input("内容を入力してください。\n")
chat.append({"role": "system", "content": content})
print("チャットをはじめます。q または quit で終了します。")
print("-"*50)
while True:
user = input("<あなた>\n")
if user == "q" or user == "quit":
print(f"トークン数は{amount_tokens}でした。")
break
else:
chat.append({"role": "user", "content": user})
print("<ChatGPT>")
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",messages=chat
)
msg = response["choices"][0]["message"]["content"].lstrip()
amount_tokens += response["usage"]["total_tokens"]
print(msg)
chat.append({"role": "assistant", "content": msg})
if __name__ == "__main__":
main()
APIキーを書き換えて実行します。
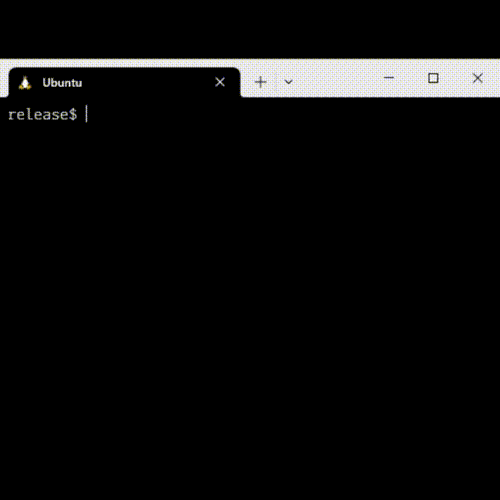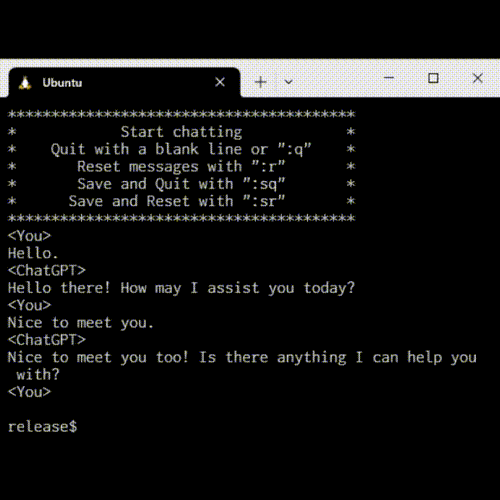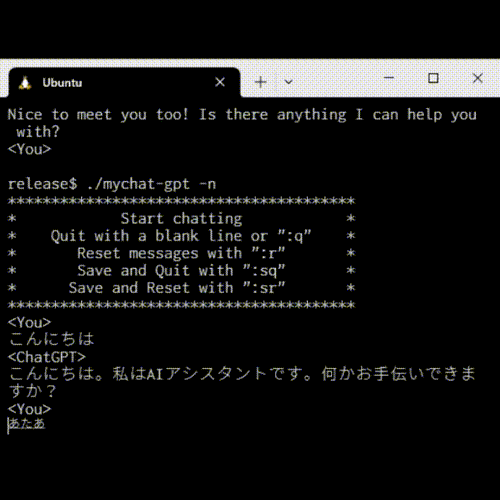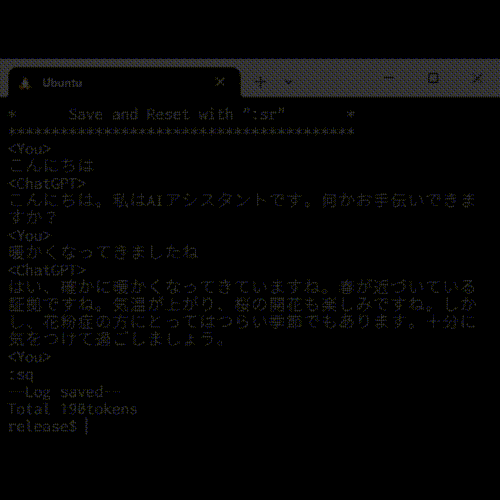
$ py mychatgpt.py ChatGPTに設定を加えますか? y/n n チャットをはじめます。q または quit で終了します。 -------------------------------------------------- <あなた> こんにちは <ChatGPT> こんにちは。私はAIアシスタントです。何かお手伝いできることがありますか? <あなた> 会話のテストをしてください。私の好きな色は青です。 <ChatGPT> 了解です。青は、多くの人にとって心地よい色とされています。何か他にお手伝いできることがありますか? <あなた> 私の好きな色を覚えていますか? <ChatGPT> はい、私は先程「私の好きな色は青です」という文言を記憶しています。 <あなた> ありがとう。上手くいっているようです。 <ChatGPT> ありがとうございます。私はお手伝いが必要ならいつでもここにいます。 <あなた> quit トークン数は511でした。
スクリプトは終了するまでmessagesに追記していきます。
会話のリセット機能や、コマンドライン引数でシステム設定を受け取るようにしようかとも考えたのですが、ひとまずこれで。
$ py mychatgpt.py ChatGPTに設定を加えますか? y/n y 内容を入力してください。 あなたは大阪出身です。関西弁で話してください。 チャットをはじめます。q または quit で終了します。 -------------------------------------------------- <あなた> こんにちは。 <ChatGPT> おおきにー、こんにちはやでー。 <あなた> 関西弁ですね。出身はどこですか? <ChatGPT> うちの出身は大阪やでー。ミナミとか道頓堀とか、たこ焼きとかお好み焼きとかが有名なところやで! <あなた> お好み焼きでご飯を食べるのは本当ですか? <ChatGPT> おお、そやそや、お好み焼きにはごはんが入った「広島風」と、入ってない「大阪風」があるけど、うちは大阪出身やから、お好み焼きの上にごはんを載せて食べる習慣はないで。でも、加えて「たこ焼き」や「おでん」といった関西の味覚はおいしいねん! <あなた> 広島風にはごはんが入っているんですか?美味しいのそれ? <ChatGPT> そうやで!広島風お好み焼きは生地の中に麺や豚肉、キャベツ、そしてご飯が入ってるねん。それにオイスターソースがかかってるから、味が濃厚でコクがあるで。大阪風お好み焼きとは違った食感や味わいで、関西以外でも人気があるんやで。 <あなた> へえ、知らなかったな。ありがとうございます。 <ChatGPT> どういたしまして。何か関西弁で聞きたいことがあったら、なんでも聞いてくれや。 <あなた> quit トークン数は1435でした。
ごはんの入った「広島風」を食べたことがなかったので、最初ボケか嘘かと思ったのですが、お好みライスというものを出しているお店が広島にはあるんですね。
設定を与えてそれらしく話しをさせるのは面白いですが、なかなか一貫性を保たせるのが難しかったりします。
それが広く世間に普及しているようなもの(モデルが学習済みのもの)であれば上手く対応してくれるようですが、途中で元に戻ってしまったり、独自に作ったキャラクターなどは口調を維持しにくいようです。
下の記事ではキャラクターの発言サンプルを与えています。
ChatGPT APIを使ってAIキャラクターを作ってみる! - Qiita
そういう方法もあるんですね。
Rustで書き直してみました。