
画像を生成するAIで、話題になって久しいStable Diffusion。
存在は前から知っていましたが、ChatGPTを試してから他のAIにも興味が出てきて、今更ながら使ってみました。
感想としては、たまにすごい当たりが出てきて、無限にできるガチャみたいでめちゃくちゃ楽しいです。
※このページではWindows、NVIDIA製のグラフィックボードを使用しているユーザーを対象としてます。
使用したときの環境
GeForce GTX 1660 SUPER
Windows10
Python 3.10.5
Git 2.35.1.windows.2
web UI作者のページ
Androidアプリを作成しました。
感情用のメモ帳です。

Stable Diffusionを使うには
ところで、手軽に試すには「Stable Diffusion Online」などがありますが、本格的に使おうと思えばいくつか方法があり、
- 自分のパソコンに環境を構築する
- Stable Diffusion web UIをインストール
- NMKD Stable Diffusion GUI(Windows)のインストール
- ローカルにいちから環境構築
- Google Colaboratory上に環境構築
- グラフィックボードがないときの選択肢
このページではタイトルにあるように1の「Stable Diffusion web UI」を導入します。
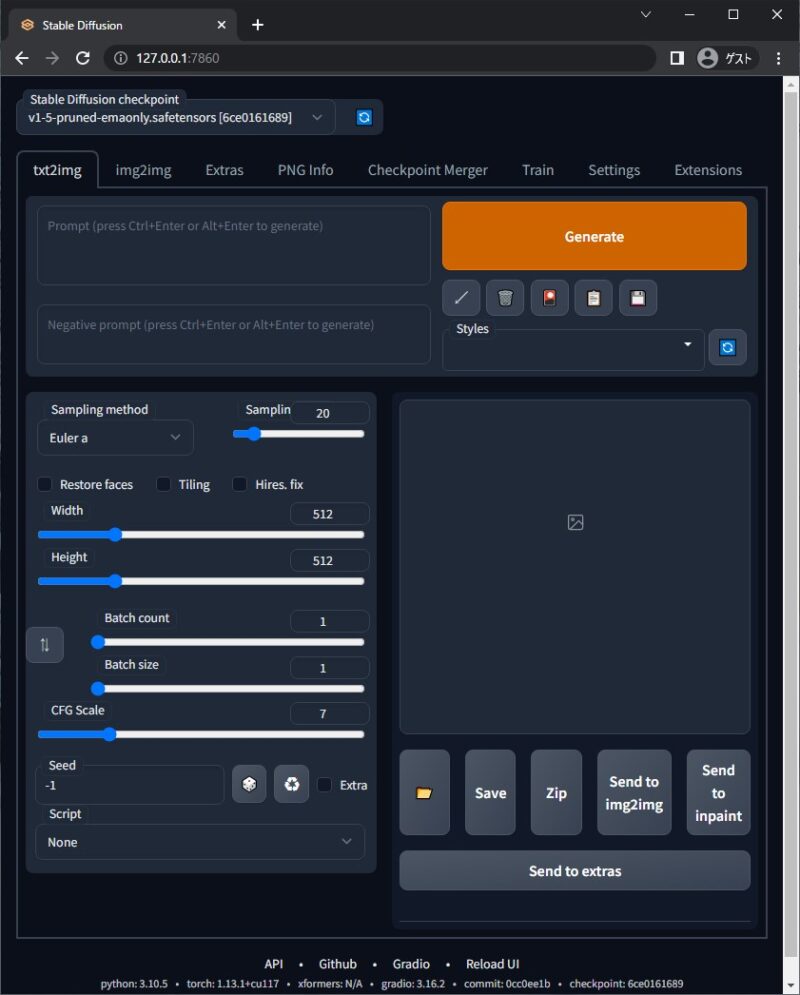
web UIは、ローカルサーバーを立て、ブラウザから使用します。
NMKD Stable Diffusion GUIは、Windowsのソフトフェアです。
どちらもStable Diffusionを開発したところとは別の方が使いやすいようにGUI化したものです。
印象としては、web UIは機能が豊富で、導入自体はGUIの方が簡単でした。
必要条件
Stable Diffusion web UIには以下のものが必要です。
- ビデオメモリ(VRAM)4GB~
- Python3.10.6
- Git
ビデオメモリ
CPU内蔵GPUではおそらく厳しいため、別途グラフィックボード(ビデオカード)が必要です。
グラフィックボードなら何でもいいわけではなく、NVIDIA製を推奨します。AMDのGPUにも対応していますが、導入方法が異なり、難易度が上がるので。
AMDのGPUユーザー向けのインストール方法
Install and Run on AMD GPUs · AUTOMATIC1111/stable-diffusion-webui Wiki · GitHub
NVIDIAのビデオカードはどれが良いか
どのビデオカードが最適? ハイエンドゲーミングPCで「Stable Diffusion」を動かすと凄い! 高解像度画像を数秒で生成【特集・集中企画】 - 窓の杜
グラフィックボードの性能では、特にビデオメモリの容量が重要になり、容量によって、画像生成速度、生成できる画像の大きさが変わってきます。
メモリが4GB以下で使用すると、メモリ不足によるエラーが起きる可能性がありますが、起動時のコマンドにオプションをつけると動くかもしれません。
私の使用する「GTX 1660 SUPER」のメモリは6GBで、「512✕512」の画像を一枚生成するのに40秒ほどかかりました。
そして生成する画像のサイズを上げると、メモリ不足からエラーが起きます。
オプションをつけると多少大きくできますが、速度も考えると10GB以上は欲しいかなと感じています。
Python
現時点(2023/2/28)では、Pythonのバージョン「3.10.6」をインストールしてください。
私は前から使っていた「3.10.5」のままで動かしましたが、動作がテストされているバージョンを使うほうがトラブルは少ないでしょう。
Python Release Python 3.10.6 | Python.org

Git
Gitはバージョンを管理するソフトフェアで、Gitがなくてもzipファイルを解凍してweb UIをインストールすることはできます。
ただ、Gitはコマンドひとつで導入やアップデートができるため便利です。
これから進めていく方法もGitを用いています。
導入
コマンドプロンプトやPowerShell、Git Bashなどを起動します。
(Windowsキー+Sで検索ボックスを起動し、cmdやpowershll、git bashなどで探せる)
ダウンロードしたいフォルダ(自分がわかりやすい場所)に移動して、以下のコマンドを実行します。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
実行すると「stable-diffusion-webui」というフォルダが作成されるので、そのフォルダに移動して、次のコマンドを打ちます。
.\webui.bat※Git Bashの場合は./webui.bat
※もしくはwebui.batを直接ダブルクリックでも構いません。
ここまでの流れをやってみます。
PowerShellを使用。
> git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git Cloning into 'stable-diffusion-webui'... remote: Enumerating objects: 16434, done. remote: Total 16434 (delta 0), reused 0 (delta 0), pack-reused 16434 6.46 MiB/s Receiving objects: 100% (16434/16434), 27.51 MiB | 16.61 MiB/s, done. Resolving deltas: 100% (11495/11495), done. > cd .\stable-diffusion-webui\ > .\webui.bat
初回は必要なものがインストールされるため時間がかかります。
しばらく待ち、
Model loaded in 3.8s (create model: 0.4s, apply weights to model: 1.0s, apply half(): 0.9s, move model to device: 0.6s, load textual inversion embeddings: 0.9s). Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.
上記のように「Running on local URL: http://127.0.0.1:7860」と出たら、サーバーが起動しています。
URLをコピーしてブラウザを起動し、アドレス欄に貼り付けてください。
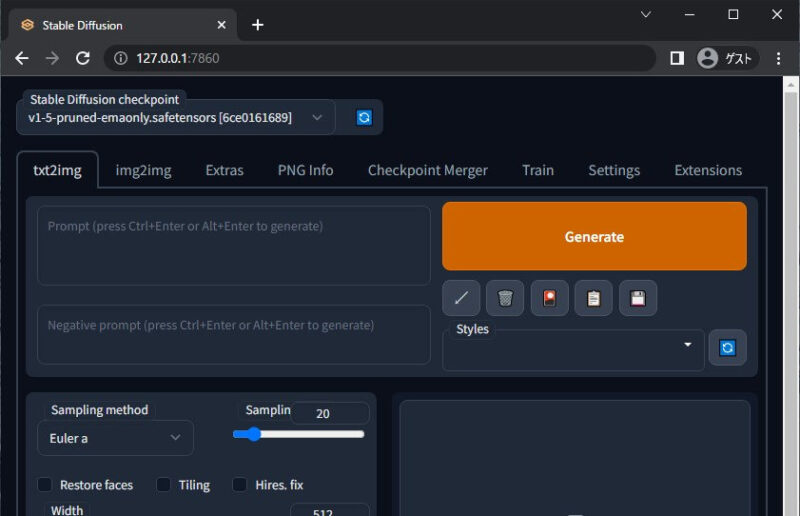
画面が表示されたら成功です。
Troubleshooting · AUTOMATIC1111/stable-diffusion-webui Wiki · GitHub
web UIを終了するには、PowerShellなどの画面に戻って「Ctrl + C」を入力します。
それから「y」か「Y」。
Interrupted with signal 2 in <frame at 0x0000026950B8AEA0, file 'C:\\Users\\fujino\\Documents\\python\\stable-diffusion-webui\\webui.py', line 173, code wait_on_server> バッチ ジョブを終了しますか (Y/N)? y
低ビデオメモリ用のオプション
ビデオメモリが4GB以下でメモリ不足によるエラーで動かなかった場合、起動時のオプションに「--medvram」をつけて試してみてください。
それでもダメなら「--lowvram --always-batch-cond-uncond」を。
.\webui.bat --medvram .\webui.bat --lowvram --always-batch-cond-uncond
メモリが4GB以上あって画像サイズを大きくしたいときにも「--medvram」か「--lowvram」でサイズアップが期待できます。
この2つのオプションは、速度を引き換えにしてメモリ消費量をおさえます。
オプションを毎回つけるのが面倒くさい?
そんなときには、「webui-user.bat」ファイルを右クリック→編集。
※webui.batファイルではありません。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--lowvram --always-batch-cond-uncond
call webui.bat上記は一例ですが「COMMANDLINE_ARGS」に自分の使いたいオプションを入れて上書きします。
そしてこっちのファイルを使って起動。
> .\webui-user.bat venv "C:\Users\fujino\Documents\python\stable-diffusion-webui\venv\Scripts\Python.exe" Python 3.10.5 (tags/v3.10.5:f377153, Jun 6 2022, 16:14:13) [MSC v.1929 64 bit (AMD64)] Commit hash: 0cc0ee1bcb4c24a8c9715f66cede06601bfc00c8 Installing requirements for Web UI Launching Web UI with arguments: --lowvram --always-batch-cond-uncond
アップグレードと削除
アップグレードするのは簡単です。
対象のフォルダに移動してから次のコマンドをつかいます。
git pullまれにバグが入ることもあるようですが、そのときはコミットを戻すか、よくわからないならあらためて別のフォルダに移動して「git clone」し、モデル等を移動させてください。
基本的にはPythonの仮想環境上にインストールされるため、難しいアンインストールの手順とかはなく、フォルダごと削除すればOKです。
画面の説明
テキストからイメージを出力する画面の説明を行います。
※アップデートによりUIが変わることがあります。
「stable Diffusion checkpoint」の下に書かれているのがモデルです。
モデルを変えると生成される画像の傾向が大幅に変わります。
初回起動時に「v1-5-pruned-~」がインストールされていたので、そのまま使えるはずです。
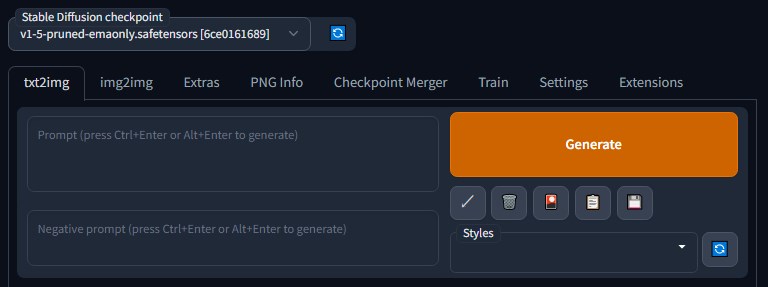
現在は「txt2img」タブを選択中です。
このモードは1つ目の枠に生成したいイメージのテキスト(Prompt)を入れ、2つ目の枠に反映させたくないもののテキスト(Negative prompt)があれば入れて、Generateボタンを押すと画像が作成されます。
※テキスト入力の際は、英語で。
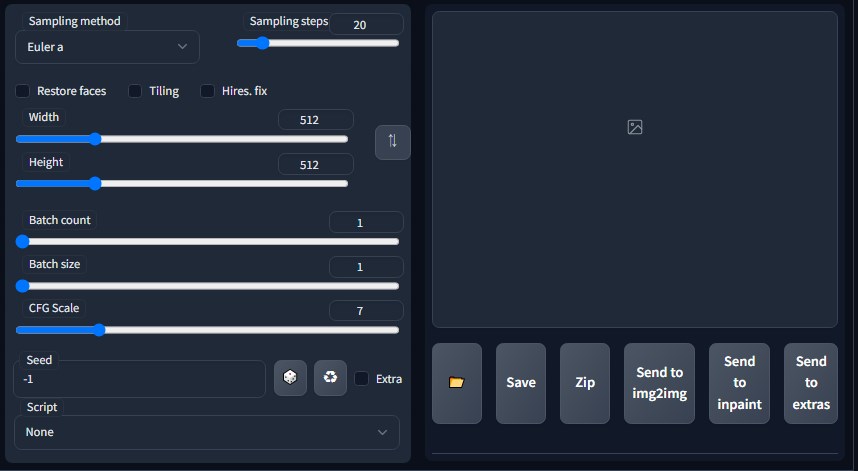
「Sampling method」を変えると、出てくる画像が多少変わります。まだメソットごとの特徴がわかるほど使いこなしていないためあしからず。
「Sampling steps」を大きくすると、高精細な画像になりますが、生成にかかる時間が増えます。ある程度まで上げると頭打ちになる印象です。
「Width」は出力画像の横幅、「Height」は縦幅。
「Batch count」は、画像を生成する回数。
「Batch size」は、一回の生成で作られる画像の枚数。メモリに余力がないなら変えない方が良。
「CFG Scale」を上げると、プロンプトの再現率が上がります。かわりに画像が崩れる確率も上がります。
「Seed」の初期値「-1」はランダムにシードを取得します。
シードを固定し、使用しているモデル、サンプリングメソッド、ステップ、画像サイズ、CFGスケールが同じであれば、基本的に同じ画像が出力されます。
右側にある枠内に画像のプレビューが表示され、フォルダアイコンのクリックで画像の保存先が開きます。
使ってみる
では使ってみましょう。
設定はデフォルトのままにして、プロンプトに「cute white cat, detailed」、ネガティブプロンプトに「low quality」を入力し、画像を生成します。
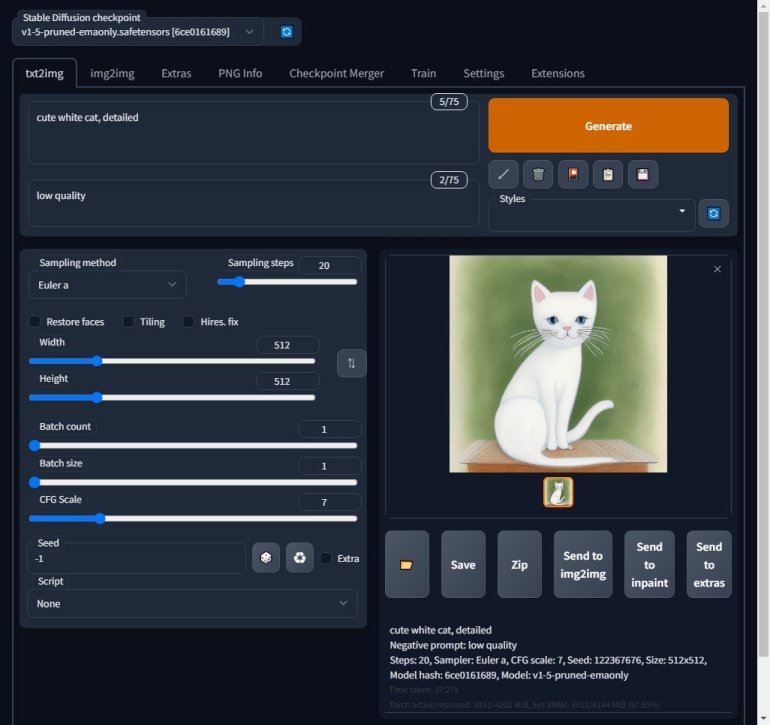
一発目で味のある絵が出てきました。
結構好きな絵です。

次はこの絵のシードを使い、ステップ数だけ「70」に変更して実行してみます。
すると、

たしかに絵の描き込みは増えていますが、ぜんぜん別の猫になってしまいました(構図も違う)。
どうやらサンプラー「Euler a」のように末尾にaがつくメソッドは、ステップ数を変えると出てくる絵がかなり変化するようです。
ではサンプラーを「Euler」にして、ステップ数を変えるとどうなるでしょうか。
※画像はJPEGに変換。

cute white cat, photo
Negative prompt: illustration
Steps: 20, Sampler: Euler, CFG scale: 7, Seed: 3290848756, Size: 512x512, Model hash: 6ce0161689, Model: v1-5-pruned-emaonly

cute white cat, photo
Negative prompt: illustration
Steps: 60, Sampler: Euler, CFG scale: 7, Seed: 3290848756, Size: 512x512, Model hash: 6ce0161689, Model: v1-5-pruned-emaonly
今度は構図も猫も同じで、ぼやけた感じがなくなり(スマホから見るとわかりにくいかも)、より高精細になっています。
ただ目の表情が変わっているため、ステップ数を上げると必ず良くなるとは言い切れないようですね。
サンプラーの違い・全サンプラーの比較【Stable Diffusion web UI(AUTOMATIC1111版) / Sampler】 – 忘却まとめ
プロンプト、サンプラー、ステップ数など、少し変えるだけでまったく違った絵が出てくるのも面白いです。
モデル
自分の望むものがはっきりしているなら、プロンプトで試行錯誤する前に、モデルを変更したほうが早いかもしれません。
本家Stable Diffusionのモデルは汎用的な画像を生成してくれますが、他にもいろいろな人がモデルを配布していて、実写が得意なモデル、イラストに特化したもの、NSFW(Not Safe For Work。職場閲覧注意、つまり性的なもの)に強いものなど様々あります。
モデルを配布しているサイト
サンプルイメージを見れば自分の好みかどうかすぐわかるはず。
ただ、倫理的な問題があるもの(許可を得ていない素材からの学習)や、商用利用不可のモデルがあるので注意してください。
モデルはダウンロードして利用しますが、ファイルの形式は2種類あって「.ckpt」か「.safetensors」です。
「.ckpt」は悪意のあるコードが実行可能なため、両方ある場合は「.safetensors」を推奨します。
モデルにはVAEが指定されていることもあるので、VAEは指定のものをダウロードして設定してください。(VAEが最適でないと色味が変な絵が出てくる)
ダウンロードしたモデルを置く場所は「models\Stable-diffusion」
ダウンロードしたVAEは「models\VAE」
大本のフォルダが「stable-diffusion-webui」だとすると、その下にある「models」のさらに下にそれぞれあります。
UIにVAEの項目を追加するには、web UIの「Settings」タブを選択、「User interface」のなかにある「Quicksettings list」に「sd_vae」を書き加えます。
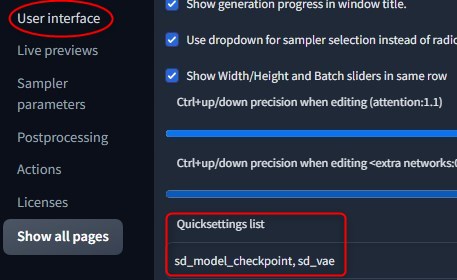
「Apply settings」ボタン、次いで「Reload UI」を押して更新すると、UIに追加されています。

∨を押してモデルやVAEを切り替えます。